csv格式文件是常用的数据存储方式,可以理解为简易版Excel,pandas支持读取csv文件
系列
附件
点击下载abc.csv
部分截图(虚构数据)
读取csv文件
pd.read_csv(path,encoding)
path : 文件路径
encoding : 编码格式,常用的有 utf-8 gbk gb2312等,查看文件编码格式见 chardet
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| import pandas as pd
path = './abc.csv'
data = pd.read_csv(path, encoding='gb2312')
print(data)
'''输出
工号 姓名 部门 绩效 提成 基本工资 是否确认
0 S1001 吕建国 销售部 100 2250 7500 是
1 S1002 张想 后勤部 100 4250 7500 是
2 S1003 王淑兰 后勤部 300 3500 6500 是
3 S1004 赵丽娟 开发部 100 2750 7500 否
4 S1005 陈利 开发部 100 1750 6000 是
.. ... ... ... ... ... ... ...
95 S1096 吴健 财务部 100 1250 9500 是
96 S1097 张小红 行政部 300 1250 6000 是
97 S1098 刘凯 运营部 100 1250 9000 是
98 S1099 王晶 运营部 100 3750 8500 是
99 S1100 潘玉华 开发部 100 4250 8000 否
[100 rows x 7 columns]
'''
|
查看csv文件数据
查看头部数据
查看所有列 : DataFrame对象.head(n)
查看某个列 : DataFrame对象['列名'].head(n) 或 Series对象.head(n)
n : 头部前n行数据,默认值5
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
head = data.head(3)
print(head)
'''输出
工号 姓名 部门 绩效 提成 基本工资 是否确认
0 S1001 吕建国 销售部 100 2250 7500 是
1 S1002 张想 后勤部 100 4250 7500 是
2 S1003 王淑兰 后勤部 300 3500 6500 是
'''
head = data['部门'].head(3)
print(head)
'''输出
0 销售部
1 后勤部
2 后勤部
Name: 部门, dtype: object
'''
|
查看尾部数据
查看所有列 : DataFrame对象.tail(n)
查看某个列 : DataFrame对象['列名'].tail(n) 或 Series对象.tail(n)
n : 尾部前n行数据,默认值5
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
tail = data.tail(3)
print(tail)
'''输出
工号 姓名 部门 绩效 提成 基本工资 是否确认
97 S1098 刘凯 运营部 100 1250 9000 是
98 S1099 王晶 运营部 100 3750 8500 是
99 S1100 潘玉华 开发部 100 4250 8000 否
'''
head = data['部门'].tail(3)
print(head)
'''输出
97 运营部
98 运营部
99 开发部
Name: 部门, dtype: object
'''
|
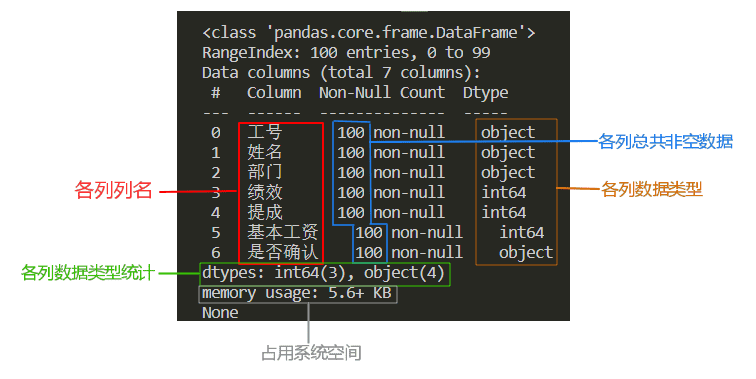
查看数据基本信息
DataFrame对象.info()
1
2
| info = data.info()
print(info)
|
查看某一列数据
DataFrame对象['列名']
DataFrame对象 的每一列是 Series对象
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
columns = data['姓名']
print(columns)
'''输出
0 吕建国
1 张想
2 王淑兰
3 赵丽娟
4 陈利
...
95 吴健
96 张小红
97 刘凯
98 王晶
99 潘玉华
Name: 姓名, Length: 100, dtype: object
'''
|
查看某一列数据的频数分布
DataFrame对象['列名'].value_counts()
或者
Series对象.value_counts()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
columns = data['部门'].value_counts()
print(columns)
'''输出
销售部 15
人力资源部 14
开发部 14
行政部 13
运营部 13
客服部 12
后勤部 11
财务部 8
Name: 部门, dtype: int64
'''
|
查看某一列数据的总量
DataFrame对象['列名'].value_counts().sum()
或者
Series对象.value_counts().sum()
1
2
3
4
5
6
7
|
columns = data['部门'].value_counts().sum()
print(columns)
'''输出
100
'''
|