requests 库请求网页数据,BeautifulSoup 库解析和提取数据,最后将提取出的数据保存为csv格式文件
环境
windows10
python3.8.6
安装库
使用 pipenv 安装
1
2
| pipenv install bs4
pipenv install requests
|
使用pip安装
1
2
| python3 -m pip install bs4 -i https://pypi.tuna.tsinghua.edu.cn/simple
python3 -m pip install requests -i https://pypi.tuna.tsinghua.edu.cn/simple
|
获取数据
下厨房本周最受欢迎菜谱链接 http://www.xiachufang.com/explore/
只提取第一页的菜谱
1
2
3
4
5
6
7
8
9
10
11
12
13
| import requests
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36'}
res = requests.get('http://www.xiachufang.com/explore/', headers=headers)
print(res.status_code)
res.encoding = 'utf-8'
html = res.text
|
解析和提取数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
items = soup.find_all('p', class_='name')
ingredients = soup.find_all('p', class_='ing ellipsis')
for item in range(len(items)):
items_all = [
items[item].find('a').text[17:-14],
ingredients[item].text[1:-1],
'http://www.xiachufang.com' + items[item].find('a')['href']
]
|
保存数据
1
2
3
4
5
6
7
8
9
10
11
12
| import csv
with open(r'下厨房本周最受欢迎菜谱.csv', 'w', newline='', encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow(['菜名', '食材', '链接'])
writer.writerow(items_all)
|
2020/11/9 爬取数据
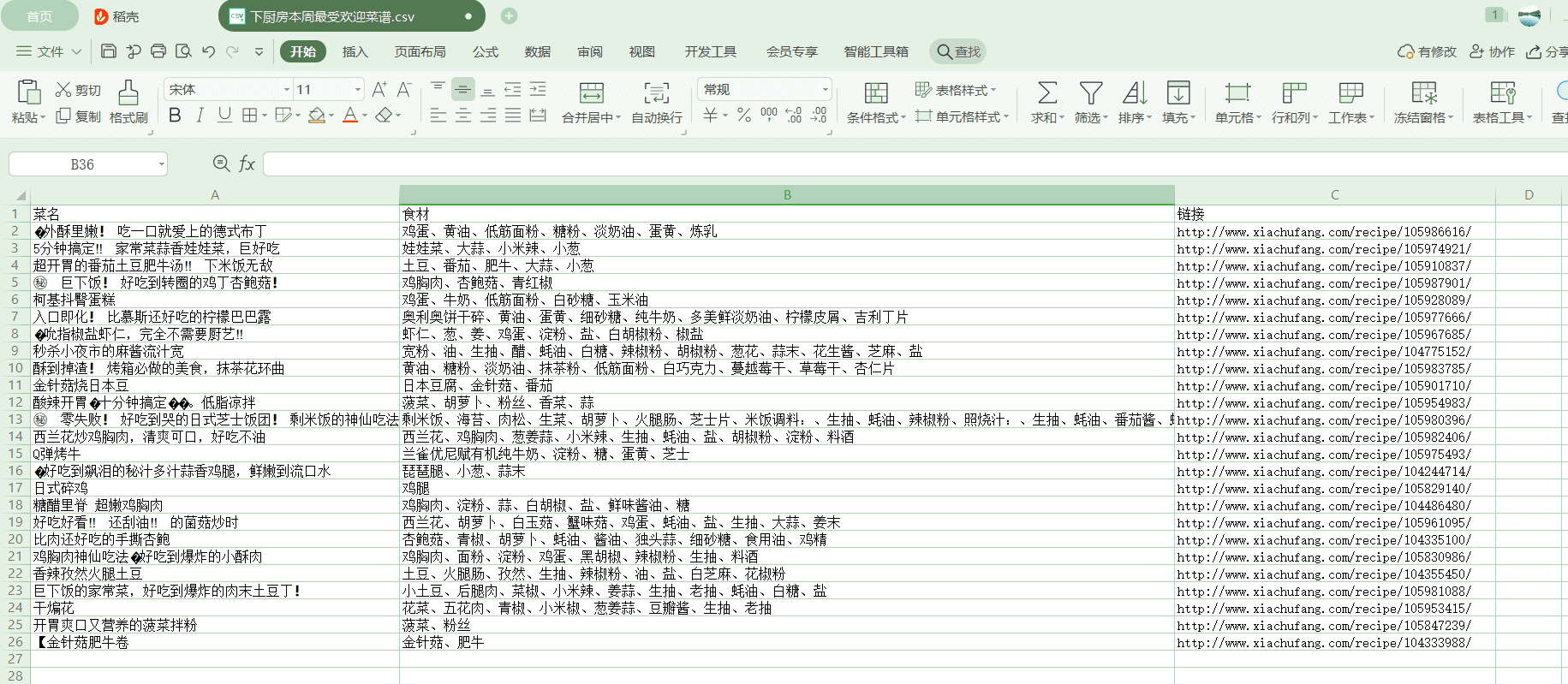
完整代码地址
完整代码