requests 库获取的数据含有大量HTML源码, BeautifulSoup 库则可以从HTML源码解析和提取出想要的数据
环境
windows10
安装库
使用pipenv 安装
1 2 pipenv install requests pipenv install BeautifulSoup4
使用pip3安装
1 2 python3 -m pip install requests -i https://pypi.tuna.tsinghua.edu.cn/simple python3 -m pip install BeautifulSoup4 -i https://pypi.tuna.tsinghua.edu.cn/simple
解析数据 语法 解析数据只需一行代码
1 bs对象 = BeautifulSoup(需要解析的文本,'解析器')
需要解析的文本 的只能是 字符串
解析器 可以使用python内置库 html.parser
实例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import requestsfrom bs4 import BeautifulSoupheaders = { 'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36' } res = requests.get('https://movie.douban.com/top250' , headers=headers) print (res.status_code)html = res.text soup = BeautifulSoup(html, 'html.parser' ) print (type (soup))
变量 html 与 soup 的打印结果相同,但对象不同,前者是 字符串 ,后者是 BeautifulSoup 对象,提取数据需要用到该对象的方法
提取数据
首先用 BeautifulSoup 对象的 find() 和 find_all() 方法对HTML源代码进行筛选(这里得到的还是含有HTML标签的源代码)
然后用 Tag 对象的方法提取出文本内容
BeautifulSoup对象
属性 class_ 加上下划线 _ 是为了区分python中的类 class ;可以使用其它属性如 name 、 style 去提取
括号内的两个参数即标签和属性名可以任选其一,也可以两个一起使用
find()
find() 方法提取出满足要求的首个数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 from bs4 import BeautifulSouphtml = ''' <div class='item'> <div class='items'>我是首个数据</div> <div class='items'>我是第二个数据</div> <div class='items'>我是第三个数据</div> </div> ''' soup = BeautifulSoup(html, 'html.parser' ) data = soup.find('div' , class_='items' ) print (type (data))print (data)
输出:
1 2 <class 'bs4.element.Tag'> <div class="items">我是首个数据</div>
find() 提取出的数据属于 Tag 对象
find_all()
find_all() 方法提取出满足要求的所有数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 from bs4 import BeautifulSouphtml = ''' <div> <div class='items'>我是首个数据</div> <div class='items'>我是第二个数据</div> <div class='items'>我是第三个数据</div> </div> ''' soup = BeautifulSoup(html, 'html.parser' ) data = soup.find_all('div' , class_='items' ) print (type (data))print (data)
输出:
1 2 <class 'bs4.element.ResultSet'> [<div class="items">我是首个数据</div>, <div class="items">我是第二个数据</div>, <div class="items">我是第三个数据</div>]
find_all() 提取出的数据是 ResultSet 对象,这其实是 Tag 对象以列表形式存储了起来,可以使用for循环提取出 Tag 对象
实例
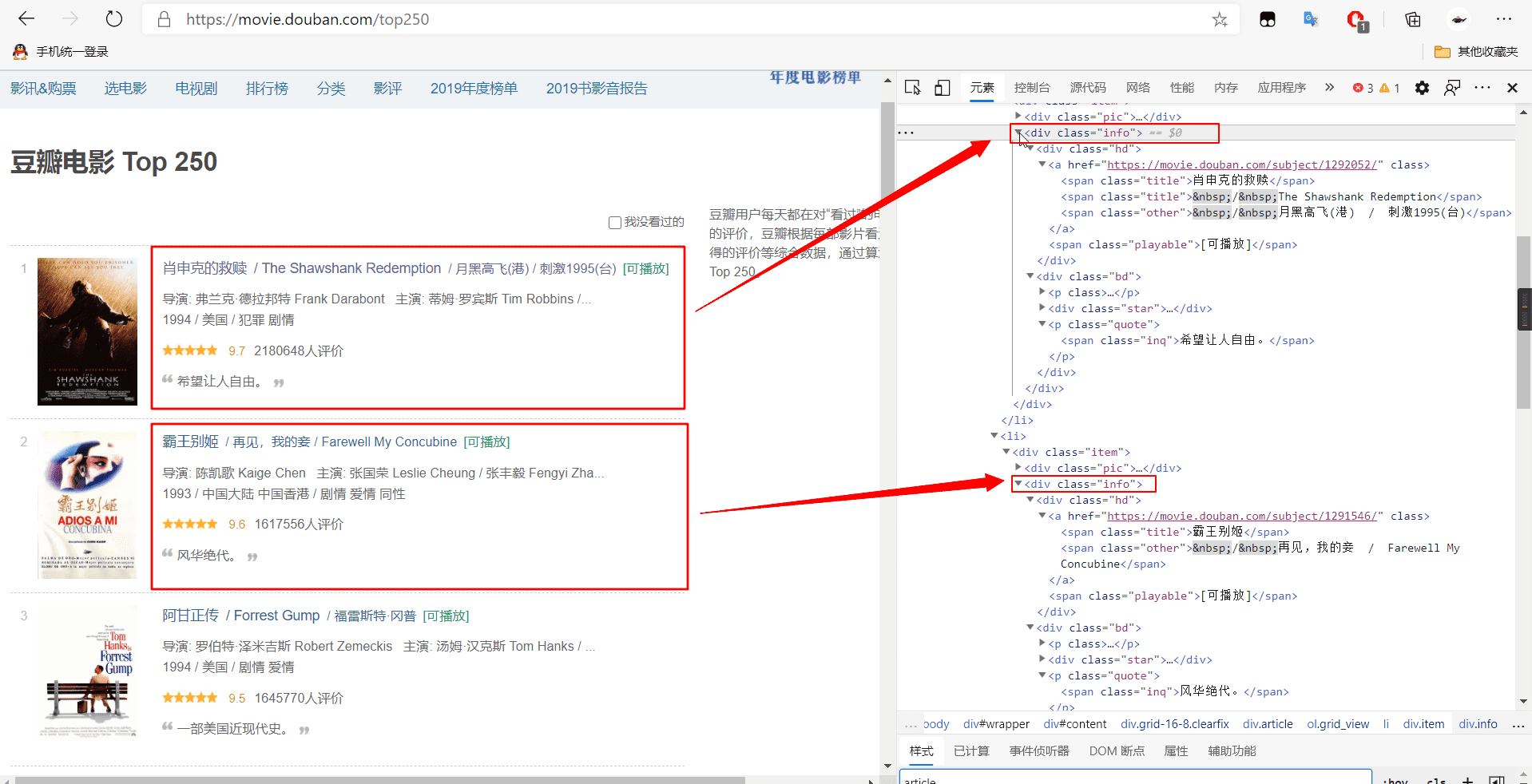
以爬取豆瓣电影为例
从图片中可以看出html源代码中每部电影包含电影名、链接和点评的最小共同父级标签是 <div class='info'>
提取出所有电影的电影名、链接和点评使用 find_all() 方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import requestsfrom bs4 import BeautifulSoupheaders = { 'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36' } res = requests.get('https://movie.douban.com/top250' , headers=headers) print (res.status_code)html = res.text soup = BeautifulSoup(html, 'html.parser' ) data = soup.find_all('div' , class_='info' ) print (data)
部分输出:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 [<div class="info"> <div class="hd"> <a class="" href="https://movie.douban.com/subject/1292052/"> <span class="title">肖申克的救赎</span> <span class="title"> / The Shawshank Redemption</span> <span class="other"> / 月黑高飞(港) / 刺激1995(台)</span> </a> <span class="playable">[可播放]</span> </div> <div class="bd"> <p class=""> 导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins /...<br/> 1994 / 美国 / 犯罪 剧情 </p> <div class="star"> <span class="rating5-t"></span> <span class="rating_num" property="v:average">9.7</span> <span content="10.0" property="v:best"></span> <span>2180648人评价</span> </div> <p class="quote"> <span class="inq">希望让人自由。</span> </p> </div> </div>, <div class="info"> <div class="hd"> <a class="" href="https://movie.douban.com/subject/1291546/"> <span class="title">霸王别姬</span> <span class="other"> / 再见,我的妾 / Farewell My Concubine</span> </a> <span class="playable">[可播放]</span> </div> <div class="bd"> <p class=""> 导演: 陈凯歌 Kaige Chen 主演: 张国荣 Leslie Cheung / 张丰毅 Fengyi Zha...<br/> 1993 / 中国大陆 中国香港 / 剧情 爱情 同性 </p> <div class="star"> <span class="rating5-t"></span> <span class="rating_num" property="v:average">9.6</span> <span content="10.0" property="v:best"></span> <span>1617658人评价</span> </div> <p class="quote"> <span class="inq">风华绝代。</span> </p> </div> </div>, ...
可以看到里面有链接、片名、点评,也有很多不必要的HTML标签
Tag对象 语法
提取出文本内容
Tag 对象也有 find() 和 find_all() 方法
属性/方法
作用
Tag.find()
提取Tag中满足要求的首个Tag
Tag.find_all()
提取Tag中满足要求的所有Tag
Tag.text
提取Tag中的文本
Tag[‘属性名’]
提取Tag中的属性值
实例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 import requestsfrom bs4 import BeautifulSoupheaders = { 'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36' } res = requests.get('https://movie.douban.com/top250' , headers=headers) print (res.status_code)html = res.text soup = BeautifulSoup(html, 'html.parser' ) data = soup.find_all('div' , class_='info' ) for i in data: ''' data是一个列表,里面的每个元素是Tag对象并赋值给变量 i a b c 也是Tag对象 通过 print(type(a)) 判断数据类型 ''' a = i.find(class_='title' ) b = i.find(class_='' ) c = i.find(class_='inq' ) print (a.text, b['href' ], c.text)
输出
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 200 肖申克的救赎 https://movie.douban.com/subject/1292052/ 希望让人自由。 霸王别姬 https://movie.douban.com/subject/1291546/ 风华绝代。 阿甘正传 https://movie.douban.com/subject/1292720/ 一部美国近现代史。 这个杀手不太冷 https://movie.douban.com/subject/1295644/ 怪蜀黍和小萝莉不得不说的故事。 泰坦尼克号 https://movie.douban.com/subject/1292722/ 失去的才是永恒的。 美丽人生 https://movie.douban.com/subject/1292063/ 最美的谎言。 千与千寻 https://movie.douban.com/subject/1291561/ 最好的宫崎骏,最好的久石让。 辛德勒的名单 https://movie.douban.com/subject/1295124/ 拯救一个人,就是拯救整个世界。 盗梦空间 https://movie.douban.com/subject/3541415/ 诺兰给了我们一场无法盗取的梦。 忠犬八公的故事 https://movie.douban.com/subject/3011091/ 永远都不能忘记你所爱的人。 海上钢琴师 https://movie.douban.com/subject/1292001/ 每个人都要走一条自己坚定了的路,就算是粉身碎骨。 星际穿越 https://movie.douban.com/subject/1889243/ 爱是一种力量,让我们超越时空感知它的存在。 楚门的世界 https://movie.douban.com/subject/1292064/ 如果再也不能见到你,祝你早安,午安,晚安。 三傻大闹宝莱坞 https://movie.douban.com/subject/3793023/ 英俊版憨豆,高情商版谢耳朵。 机器人总动员 https://movie.douban.com/subject/2131459/ 小瓦力,大人生。 放牛班的春天 https://movie.douban.com/subject/1291549/ 天籁一般的童声,是最接近上帝的存在。 大话西游之大圣娶亲 https://movie.douban.com/subject/1292213/ 一生所爱。 熔炉 https://movie.douban.com/subject/5912992/ 我们一路奋战不是为了改变世界,而是为了不让世界改变我们。 疯狂动物城 https://movie.douban.com/subject/25662329/ 迪士尼给我们营造的乌托邦就是这样,永远善良勇敢,永远出乎意料。 无间道 https://movie.douban.com/subject/1307914/ 香港电影史上永不过时的杰作。 教父 https://movie.douban.com/subject/1291841/ 千万不要记恨你的对手,这样会让你失去理智。 龙猫 https://movie.douban.com/subject/1291560/ 人人心中都有个龙猫,童年就永远不会消失。 当幸福来敲门 https://movie.douban.com/subject/1849031/ 平民励志片。 怦然心动 https://movie.douban.com/subject/3319755/ 真正的幸福是来自内心深处。 触不可及 https://movie.douban.com/subject/6786002/ 满满温情的高雅喜剧。